Sjef Barbiers (Meertens Institute) – Ineke Schuurman (KU Leuven)
1. Introduction
In this case study we use two software tools, MIMORE and GrETEL. We use MIMORE to investigate a syntactic property of the Dutch dialects and then we use GrETEL to see if and how this property influences lanugage use in non-dialectal, i.e. colloquial and standard Dutch.
All varieties of Dutch are asymmetric verb second languages. This means that all verbs line up at the end of the clause in a so called verb cluster (1a), except finite verbs in clauses without a complementizer. In such clauses the finite verb is in the position of the complementizer (cf.1b,c). This position is called the verb second position because maximally one constituent can precede the finite verb. These varieties are called asymmetric because in the unmarked case the finite verb is in the verb second position in main clauses and at the end of the clause in dependent clauses (1d,e).
(1) a. Ik vind
dat hij de wagen voor 3 uur moet hebben gemaakt.
that he the car before 3 o’clock must have made
‘I think that he should have repaired the car before 3 o’clock.’
b. Als zij komt (dan brengt zij taart mee).
if she comes (then brings she cake with)
‘If she comes she will bring cake.’
c. Komt zij (dan brengt zij taart mee).
comes she then brings she cake with
‘If she comes she will bring cake.’
d. Hij eet een appel.
he eats an apple
e. (Ik denk) dat hij een appel eet.
I think that he an apple eats
‘I think that he is eating an apple.’
The word order of the three verbs in the verb cluster in (1a) is not fixed. In the first part of the case study we ask two questions: (i) Which of the six logically possible orders occur in the Dutch language area? (ii) What is the geographic distribution of these orders?
2. Verb clusters in MIMORE
The six logically possible orders of the verb cluster in (1a) are given in (2).
(2) Ik vind dat hij voor drie uur de wagen
I think that he before three hour the car
a. moet hebben gemaakt 1-2-3
must have made
b. moet gemaakt hebben 1-3-2
c. gemaakt moet hebben 3-1-2
d. gemaakt hebben moet 3-2-1
e. hebben moet gemaakt 2-1-3
f. hebben gemaakt moet 2-3-1
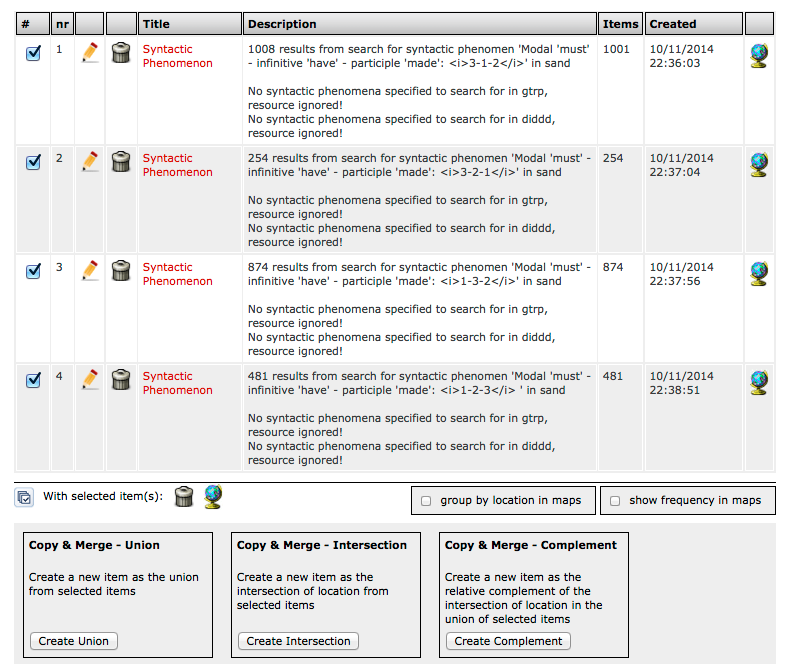
To find out which of the logically possible word orders in (2) occur we use two functions of MIMORE: the functions Search for Tags and Search for Syntactic Phenomena. The first works with the raw data and comes with a Tag Constructor. We can construct our own string of tags and search with this string. We will first search for the order gemaakt hebben moet (3-2-1). The first step is to choose the category V from the list of categories. This category then appears in the search field. Next we specify the verb by choosing ‘participle’ from the list of features. We now have V(participle) in the search field (figure 1).
Figure 1

We repeat this for the second verb, V(aux) (aux = auxiliary), and for the third V(mod) (mod = modal) (figure 2).
Figure 2
The result of this search is a list of georeferenced sentences, as illustrated in figure 3.
Figure 3

The result can also be presented on a map:
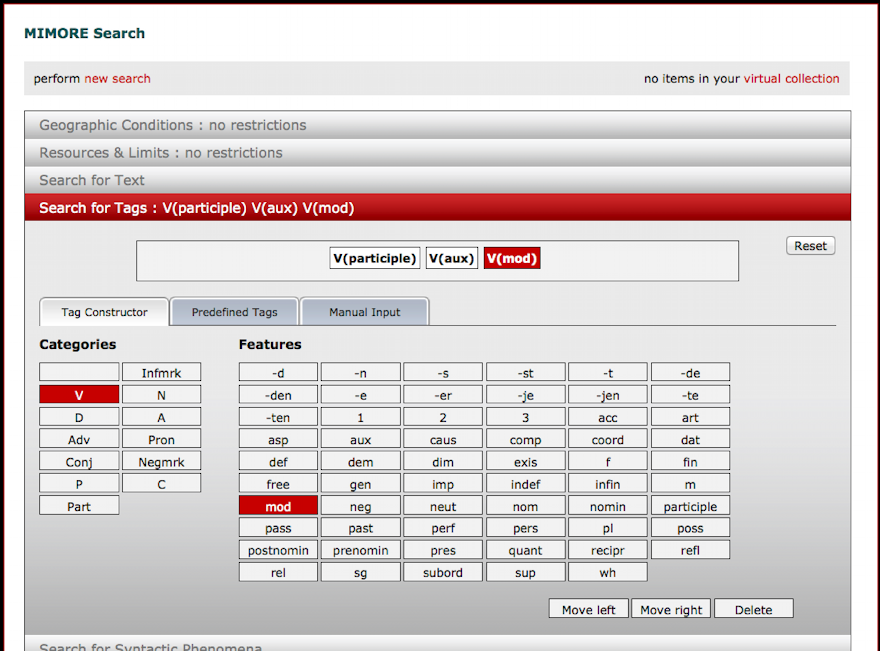
Map 1: Geographic distribution of the order 3-2-1
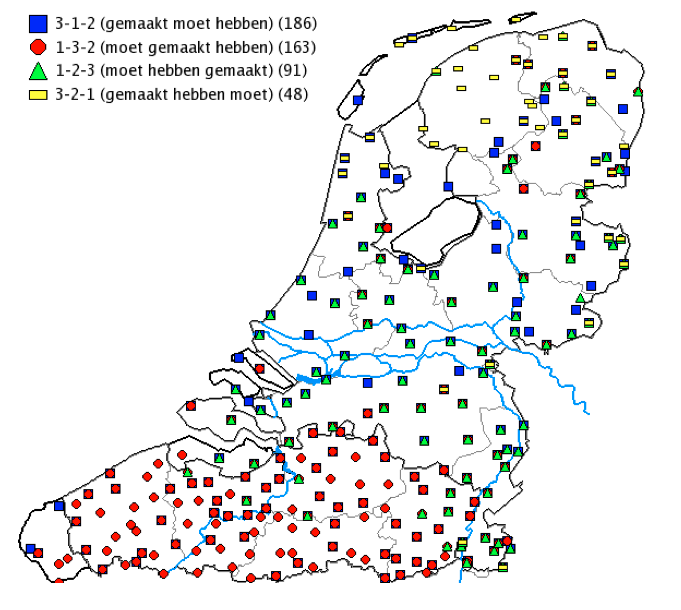
Map 1 shows that the 3-2-1 order has a clear geographic distribution. It almost exclusively occurs in the north (Noord-Holland, Friesland, Groningen, Drenthe) and along the eastern border. This is a preliminary presentation. Before using such a map in an official publication or lecture it is necessary to go through the list of search results to see if they all fit the requested description. The ones that don’t can be deselected before the map is drawn.
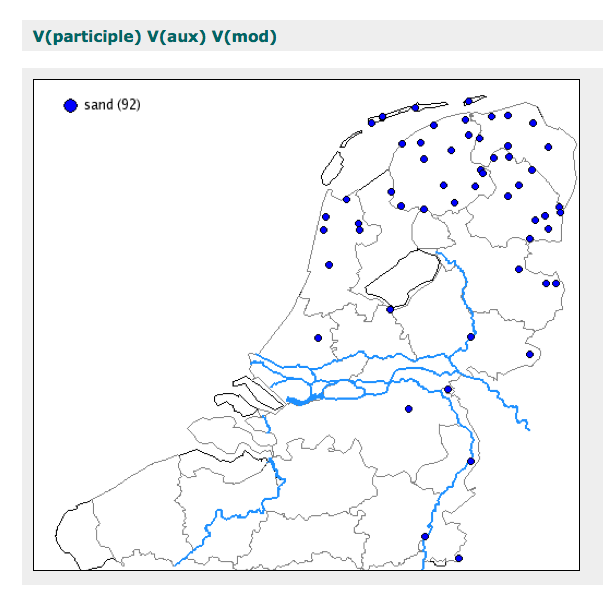
Next we investigate the order 1-3-2 (moet gemaakt hebben) by using the function Search for Syntactic Phenomena. This function works with the data that were selected for the Syntactic Atlas of the Dutch Dialects, Volume II. In other words, every single search result was checked to see if it was reliable. Map 2 shows that this order predominantly occurs in the southern part of the language area (Vlaanderen, Brabant and Limburg).
Map 2: Geographic distribution of the order 1-3-2
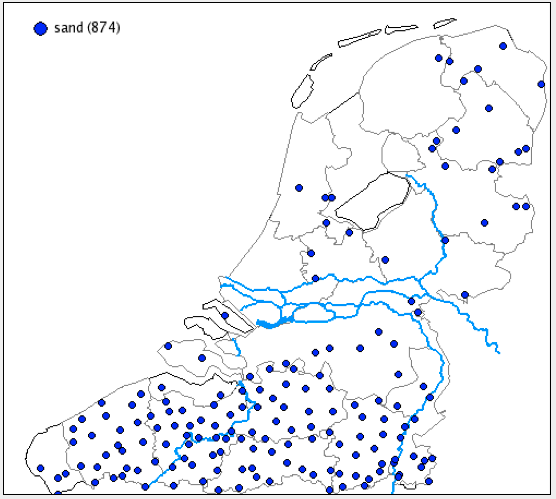
Using the same function for the orders 2-1-3, 2-3-1, 1-2-3, 3-1-2, we find that the first two do not occur at all, the order 1-2-3 has a distribution that is more or less complementary to the orders 3-2-1 and 3-1-2 (map 3) while the order 3-1-2 occurs everywhere except in Friesland (map 4).
Map 3: Distribution of the order 1-2-3
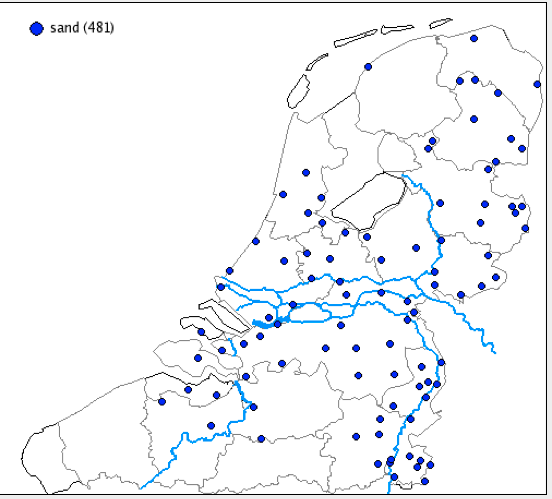
If we combine these results in one map (not yet possible in MIMORE, but available in DynaSAND, sand.meertens.knaw.nl), we get the map in 4.
Map 4: Combined results
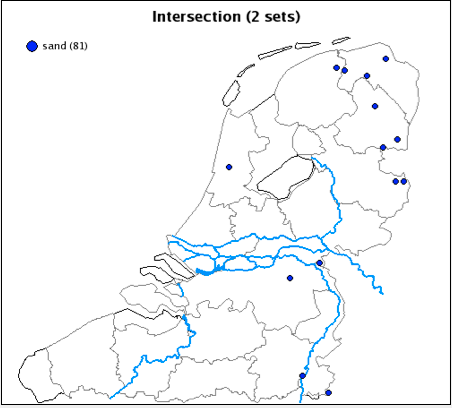
In MIMORE it is possible to construct the intersection of the four possible orders. This will give us a map that shows the geographic distribution of dialects that allow for more than one word order. We procede as follows. First we repeat the searches above, but now we add each set of search results to the virtual collection (figure 4).
Figure 4: Search results in virtual collection
We can then construct the various intersections. For example, map 5 shows the geographic distribution of dialects that have both the order 3-2-1 and the order 1-3-2. We find that those primarily involves northern Saxon dialects.
The question we ask in the next section is whether the geographic distribution of these word orders influences the frequency of use of particular orders in colloquial and standard Dutch. For example, is it the case that southern speakers of standard or colloquial Dutch use the order 1-3-2 more frequently than northern speakers? This question will be investigated with GrETEL.
Map 5: Intersection of dialects with order 3-2-1 and order 1-3-2
3. Verb clusters in GrETEL
Using the same types, forms and orders of verbs as mentioned in (2), we get results as shown in the figures below for CGN (spoken language) and Lassy (written language).
The results in section 2 are based on elicited answers in interviews etc. : “is this a correct phrase in your dialect.”, “how would you say this in your dialect.”
The results in section 3 are not based on dialects, but on a more standard (variant of) Dutch as used in Flanders or the Netherlands.1 And they are based on the way constructions are really used in daily life.
In this section we concentrate on sentences in which verb clusters occur with a finite modal verb, an infinitival temporal auxiliary (‘hebben’ or ‘zijn’) and a past participle, the main verb.
The example sentence
(3) dat hij voor drie uur de wagen moet hebben gemaakt
entered in GrETEL (Figure 5) will be automatically parsed by Alpino, returning the tree structure shown in Figure 6. Note that the Advanced search mode was selected, as this allows us to at a later stage to adapt the query, i.e., making it more general.
Figure 5: Step1 (example sentence + search mode)

Figure 6: Step2 (parsed sentence)

The matrix selection used is shown in Figure 7. We are only interested in subclauses, and in verbs showing up in a particular order. So we checked off the option Respect word order, and NOT the option Ignore properties of the dominating node.
In the matrix all words except for the verbs are said to be optional, for the finite verb (moet) and the past participle (gemaakt) we selected ‘detailed word class’, making clear that any finite verb or past participle will do,2 while for the infinitive we are a little bit more specific, stating that it should be ‘hebben’ by checking off the lemma-option.3
Figure 7: Step3 (important elements)

In a next step the treebank to be used can be selected (in this use case CGN and LASSY), whereas in Step 5 the XPath query resulting from the indiaction in Step 3 is shown. In Advanced search mode for CGN and Lassy, this XPath query can be adpated.
The original (automatically generated) XPath query is:
//node[@cat="ssub" and node[@rel="hd" and @pt="ww" and @pvtijd="tgw" and @wvorm="pv" and @pvagr="ev" and number(@begin) < number(../node[@rel="vc" and @cat="inf"]/node[@rel="hd" and @pt="ww" and @lemma="hebben"]/@begin)] and node[@rel="vc" and @cat="inf" and node[@rel="hd" and @pt="ww" and @lemma="hebben" and number(@begin) < number(../node[@rel="vc" and @cat="ppart"]/node[@rel="hd" and @pt="ww" and @wvorm="vd" and @positie="vrij" and @buiging="zonder"]/@begin)] and node[@rel="vc" and @cat="ppart" and node[@rel="hd" and @pt="ww" and @wvorm="vd" and @positie="vrij" and @buiging="zonder"]]]]
In a more readable (beautified) version:
//node[
@cat="ssub" and
node[
@rel="hd" and
@pt="ww" and
@pvtijd="tgw" and
@wvorm="pv" and
@pvagr="ev" and
number(@begin) < number(../node[
@rel="vc" and
@cat="inf"
]/node[
@rel="hd" and
@pt="ww" and
@lemma="hebben"
]/@begin)
] and
node[
@rel="vc" and
@cat="inf" and
node[
@rel="hd" and
@pt="ww" and
@lemma="hebben" and
number(@begin) < number(../node[
@rel="vc" and
@cat="ppart"
]/node[
@rel="hd" and
@pt="ww" and
@wvorm="vd" and
@positie="vrij" and
@buiging="zonder"
]/@begin)
] and
node[
@rel="vc" and
@cat="ppart" and
node[
@rel="hd" and
@pt="ww" and
@wvorm="vd" and
@positie="vrij" and
@buiging="zonder"
]
]
]
]
This XPath query can be made more general, stating that
- the finite verb can does not need to have the present tense, or be a singular form (deleting these features)
- Stating that the temporal auxiliary might also be zijn (to be)
This results in the adapted XPath query:
//node[@cat="ssub" and node[@rel="hd" and @pt="ww" and @wvorm="pv" and number(@begin) < number(../node[@rel="vc" and @cat="inf"]/node[@rel="hd" and @pt="ww" and (@lemma="hebben" or @lemma="zijn")]/@begin)] and node[@rel="vc" and @cat="inf" and node[@rel="hd" and @pt="ww" and (@lemma="hebben" or @lemma="zijn") and number(@begin) < number(../node[@rel="vc" and @cat="ppart"]/node[@rel="hd" and @pt="ww" and @wvorm="vd" and @positie="vrij" and @buiging="zonder"]/@begin)] and node[@rel="vc" and @cat="ppart" and node[@rel="hd" and @pt="ww" and @wvorm="vd" and @positie="vrij" and @buiging="zonder"]]]]
In beautified version:
//node[
@cat="ssub" and
node[
@rel="hd" and
@pt="ww" and
@wvorm="pv" and
number(@begin) < number(../node[
@rel="vc" and
@cat="inf"
]/node[
@rel="hd" and
@pt="ww" and
(@lemma="hebben" or @lemma="zijn")
]/@begin)
] and
node[
@rel="vc" and
@cat="inf" and
node[
@rel="hd" and
@pt="ww" and
(@lemma="hebben" or @lemma="zijn") and
number(@begin) < number(../node[
@rel="vc" and
@cat="ppart"
]/node[
@rel="hd" and
@pt="ww" and
@wvorm="vd" and
@positie="vrij" and
@buiging="zonder"
]/@begin)
] and
node[
@rel="vc" and
@cat="ppart" and
node[
@rel="hd" and
@pt="ww" and
@wvorm="vd" and
@positie="vrij" and
@buiging="zonder"
]
]
]
]
Note that the ‘query tree’ graphically reflecting the original query remains the same!
On basis of the modified XPath query, the search can be started. The results will be presented in Step 6.
The search is to be repeated for the other corpus as well, and for all 6 constructions (cf sentences 2 a/f) .4
For subordinate clauses, cf. the examples in (2), the results are the following:
Figure 8: Modal-temp aux-main (all orders) clusters
|
|
CGN |
CGN-NL |
CGN-VL |
LASSY |
Sum |
|
1-2-3 |
26 |
19 |
7 |
66 |
92 |
|
1-3-2 |
3 |
0 |
3 |
2 |
5 |
|
3-1-2 |
17 |
14 |
3 |
33
|
50 |
|
3-2-1 |
0 |
0 |
0 |
0 |
0 |
|
2-1-3 |
0 |
0 |
0 |
0 |
0 |
|
2-3-1 |
0 |
0 |
0 |
0 |
0 |
|
Sum |
46 |
33 |
13 |
101 |
147 |
For CGN, the spoken Dutch corpus, the hits can be split up for data originating from the Netherlands (CGN-NL) and data from Flanders, the Dutch-speaking part of Belgium (CGN-VL).
For the order 1-3-2 only a few constructions are found, 5 in total. Those found in CGN all occur in a sub-corpus containing read speech (like books for blind people), i.e. in written (!) language. The orders 1-2-3 and 3-1-2 are the common ones, both are more common in written speech. Note that in CGN, there is a 2/3 – 1/3 division between Dutch (CGN-NL) and Flemish (CGN(VL). This means that especially for the orders 1-3-2 and 3-1-2 the hits are not more or less balanced.
Whereas the order 3-2-1 is not found in either LASSY or CGN, it is considered a valid option in the Mimore-part (section …). We therefore also had a look at the SONAR-corpus (500M words), but even in that large corpus we did not find a matching sentence.
Due to its size, SONAR cannot be queried with an adapted XPath query, i.e., one that was made more generic. We therefore had to use several input sentences.
(3) a dat hij de wagen voor drie uur gemaakt hebben moet
b dat hij de wagen voor drie uur gemaakt hebben moest
c dat zij de wagen voor drie uur gemaakt hebben moeten
d dat zij de wagen voor drie uur gemaakt hebben moesten
The sentences 3c and 3d could not be analyzed properly by the Alpino-parser, it considers hebben (have) to be the finite verb, and therefore does not know what to do with moe(s)ten (must), the verb that makes the sentence ungrammatical.
The verbs used as finite verb in the above mentioned subordinate sentences are shown in Figure 9.
Figure 9: Finite forms
|
|
CGN |
LASSY |
sum |
|
Kunnen |
2 |
5 |
7 |
|
Moeten |
4 |
17 |
21 |
|
Willen |
1 |
0 |
1 |
|
Zullen |
39 |
79 |
118 |
|
Sum |
46 |
101 |
147 |
In Haeseryn et al (1997) a series of verbs is mentioned as candidate modal verbs.5 These verbs are listed below:
- kunnen (can),
- moeten(need, have to),
- (be)hoeven(need),
- mogen (may),
- willen(want),
- zullen(will)
We only found 4 of these in ‘our’ constructions: verb clusters of at least 3 verbs containing a finite modal verb, an infinitival temporal auxiliary (‘hebben’ or ‘zijn’) and a notional verb occurring as past participle. (be)hoeven and mogen do not occur at all. But note that also kunnen and especially willen are rarely used. In fact this turns out to hold for the construction as a whole.
Together LASSY and CGN contain 194,923 sentences: 65,000 (LASSY) and 129.923 (CGN). Only in a small percentage of these sentences, a subordinate clause is contained showing the pattern under discussion: maximally 147 times !6 That is in less than 0.1% ! The division LASSY – CGN is more or less 2/3 – 1/3, i.e., far more cases in written language, the same division more or less can be made for Dutch vs Flemish, but note that this reflects the difference in size.
Figure 10: distribution over the corpora
|
|
moeten |
kunnen |
willen |
zullen |
|
L-123 |
9 |
3 |
0 |
54 |
|
C-123 NL |
2 |
0 |
0 |
17 |
|
C-123 VL |
0 |
1 |
0 |
6 |
|
L-132 |
1 |
1 |
0 |
0 |
|
C-132 NL |
0 |
0 |
0 |
0 |
|
C-132 VL |
2 |
0 |
0 |
1 |
|
L-312 |
7 |
1 |
0 |
25 |
|
C-312 NL |
0 |
0 |
1 |
12 |
|
C-312 VL |
0 |
1 |
0 |
3 |
For CGN, metadata are available with information per document about the speakers involved, like their residence. Currently this information is not available via GrETEL.7 Such information allows us to compare the data available via MIMORE (section 2). Since MIMORE does not contain data on ‘zullen’, the verb ‘zullen’ is not taken into account, we will ignore constructions with ‘zullen’ as well, in order to get a fair comparison.
Figure 11: some locations
|
|
hits |
location |
|
C-123 NL |
2 |
fnj007197- region unknown fnk003639 - prov. Utrecht |
|
C-123 VL |
1 |
fvo801155- irrelevant |
|
C-132 VL |
2 |
fva400219 - prov. of Antwerp fva400503 - West-Vlaanderen |
|
C-312 NL |
1 |
fne000873- Noord-Brabant |
|
C-312 VL |
1 |
fvo801285 - irrelevant |
In the table above the locations of the hits in CGN are mentioned. In one case, however, the location is unknown, in two other cases the location is known, but we consider it irrelevant: these files concern read-aloud books, in such cases knowing where the speaker is from does not say anything at all about the syntactic constructions used.8 In one case the location is unknown, it concerns a newsflash on the radio.
The other four locations are in line with the maps presented in the MIMORE-section.
Conclusion
Whereas MIMORE and GrETEL are designed for completely different purposes, they can be used in combination to look at the findings in another perspective: ‘which constructions are considered to be correct’ vs ‘which constructions are actually used’.
This would especially be the case when MIMORE and GrETEL would handle the same languages/dialects (adding elicitations for Dutch to MIMORE, and treebanks for dialects to GrETEL).
But already in the present context it is nice to be able to see whether characteristics of dialects also show up when speakers of these dialects are using ‘standard’ Dutch as shown in the present case study. Apart from these results, in one of the hits with ‘zullen’ as modal verb, as past participle for ‘kunnen’ the form ‘gekunnen’ showed up, instead of ‘gekund’. This form is not commonly used in standard Dutch, but using the metadata of CGN, and the MIMORE-tool we found that this form showed up in GrETEL at a location where it is also commonly used in the dialect (cf. SAND, vol II, map 37a). So it is not just an error as often seen in spoken language, but an existing form based on dialect.
Using both tools in combination may open up new perspectives for research!
Notes
↩︎ 1. In CGN (spoken Dutch) the speakers were explicitly asked to speak Dutch instead of their dialect. Still, in quite some recordings, and the transcriptions thereof, the language used has dialectical characteristics.
↩︎ 2. Guessing that in the constructions on hand, the finite verbs will mainly be (functioning as) modal verbs.
↩︎ 3. We could have chosen ‘word’ as well. Note that from bottom to top the selection becomes more specific. Choosing the option ‘word’ vin this case will only return hits where ‘hebben’ functions as infinitive, not as finite verb (plural present) .
↩︎ 4. The easiest way to do this is to perform one and the same search action for both corpora, before switching to the following construction.
↩︎ 5. Zullen, for example, will often be used to express the future
↩︎ 6. This number suggests that all hits found indeed contain a finite modal verb. Especially for the verb ‘zullen’ this is not always the case.
↩︎ 7. It will be made available in a new release.
↩︎ 8. And while we do know who the authors are (Paul Koeck (De bloedproever) and Hugo Claus (Onvoltooid verleden)), this is not informative either, as books are typically corrected by editors.